处理器的微架构
一个民族有一些关注天空的人,他们才有希望。
我们在硬件构建的世界里编写代码,在CPU的跳动声中运行代码,如果不去关心这一切是如何实现的,我们程序的效率必定会达到一个认知的瓶颈。在那时,我们自以为自己的代码已经达到完美,殊不知在那只是一个里程碑式的开始。
今天这篇文章主要谈及的是处理器的微架构的流水线作业部分:
流水线
流水的思想
如果程序的执行被限定为逐步依次执行的话,那么提高CPU的速度无非是提升主频、加快数据传输。然而数电的知识告诉我受限于三极管的高频效应,当达到MHz级别之后,将元器件允许的频带每拓展100MHz都将是一个巨大的挑战。而流水线的引入是一个巨大的突破,将频带的拓宽不再仅仅决定于硬件本身特性,更决定硬件电路的算法,而理解流水线的工作原理对理解多线程也有很大帮助。
借用了工厂中流水线的模型,我们把一条指令的实现分为几个步骤交给几个部件去实现(一般尽可能地分成等时长的步骤,否则可以增多执行长时间步骤的部件数量。):取指令、译码、执行(这只是一个最基本的模型)。那么指令的实现就可以如下表示: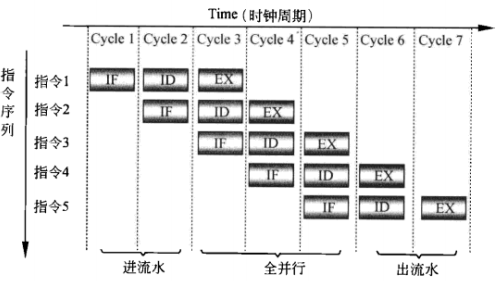
很显然,在等时长的理想情况下,处理速度一下子变为了以前的三倍。(IF:取指令,ID:译码,EX:执行)
但是,等时长只是一个假设,如果(事实上也是肯定的)各个步骤长短不一,那就无法避免地会出现节拍混乱(即如前一指令EX还未执行完成,这一条EX却已经开始了)。处理器采用寄存器作为缓冲,先把此时钟周期完成的步骤的值存在寄存器中,然后再下一周期开始时才把数据传给右端节拍。这样,寄存器就像一个红绿灯一样,在同步操作中占有重要地位。

流水线的冒险
并行虽然加快了速度,却不可避免地带来了更多的硬件上的冲突,所以也可以是达到瓶颈后必经的历练:
结构冒险:在当前后指令需要对同一资源进行访问的时候发生。比如第一条指令的读取存储器步骤(MEM)与第四条指令的(从存储器)取指令需要对同一存储器进行访问时,就会发生冲突。
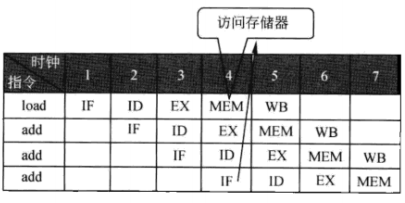
这并不是程序员需要关心的,现代的硬件电路设计已经让编译器具有了智能调度的能力。
数据冒险:在第二条指令用到了第一条指令正在修改的数据时发生。这样往往需要通过延迟一周期或者满足一定条件地直接从寄存器中加载修改后的数据。
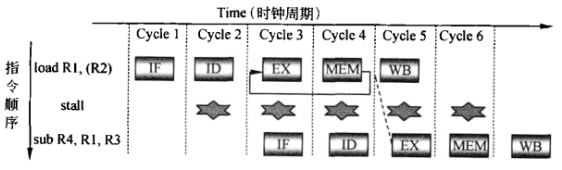
不得不说如果以一定次序进行编码,并且编译器采用顺序执行(而非之后要提到的乱序执行),这是无法避免的损失。另外我们并不知道一条指令会被机器拆成多少个步骤,当然如果能降低毗邻代码的耦合度,则能对所硬件平台都能避免数据冒险的发生。
控制冒险:在跳转语句时发生。因为站在汇编语言的角度,一旦发生跳转,几条正在装载的语句的步骤都失去了意义,根据不同的硬件平台,消除这些加载的数据都会降低一定的效率。而当循环次数很多的时候,效率的降低将是非常明显的。
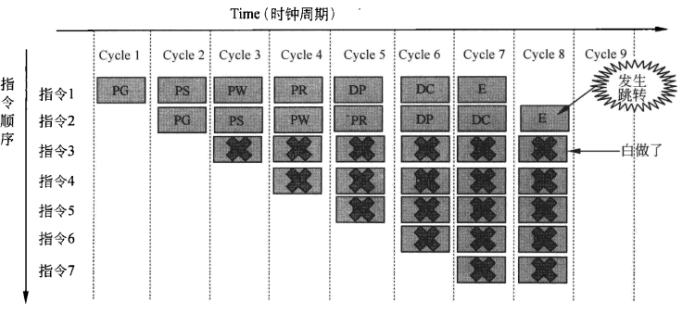
然而这也不是程序员需要操作的事情(只是为了之后的理解),因为硬件逻辑在很大程度上规避了这样的问题。通过之后提到的,记录以往发生跳转的记录对此次跳转位置进行记录,然后从预测点开始预加载步骤,这样就不会浪费资源,而在追求功耗的DSP中会讲工作交给程序员。
从顺序到乱序
因为硬件上的限制,访问内存的速度是很慢的(当然还有一些其他的耗时间的操作,这只是一个例子)虽然一些编译器能够智能地根据数据的使用频率将数据加载到不同级别的缓存当中,然而仍可以充分地利用等待读取数据的时间:优先进行不依赖于正在被读取的数据的指令。
首先需要知道如何判定是否相互依赖呢?应该找到两条指令发生依赖关系原因,而它们往往是以下两点(从汇编语言的角度):
1、寄存器相关
在指令中用到了相同的寄存器,事实上它们并不一定有相关性,有可能只是因为可见的寄存器太少了。
2、控制相关
程序中的条件跳转指令影响到了程序的走向。如紧跟在CMP指令后的JNZ指令。这里的优化主要是编译器的工作,可以根据以往的经历对未来的跳转位置进行预测。
以上两点提醒我以后编写对效率要求很高的程序时:
1)尽量去除数据相关。例如:
x = a + b;y = x + c;z = y + d;
可以改写为:
x = a + b;y = c + d;z = x + y;
2)尽量去除实际并不相关的相关。例如:
C=A+B;F=D+E;
本来是不相关的,但是由于用户可见的寄存器太少了,变量会映射到同一个寄存器上,它们就像伪军一样是可以争取的对象,具体方法是通过对每条指令的目的寄存器映射到新的物理寄存器来解除依赖关系。(当然这样费神的工作也只有核心程序值得这样付出了)。
总结与思考
有人说程序=算法+数据结构,然而我想这句话只适合很久的处理器结构,我想应该改写为程序=算法+数据结构+底层优化。
我们的客户的耐心越来越少,而节约服务器的耗费也是一个让人信服的理由,现在的电脑大多都是多核,在设计、编程时面向多线程进行开发能节省得更多,而这往往是一些细节,如果了解一些CPU的实现,在实现时也将多一份方向。另外在一些核心程序遇到瓶颈时(因为编译器的优化也不是绝对智能的),可以试着查看汇编源码,甚至可以针对程序所运行的机器对变量做一些调度(当然这也往往是在商业级的服务器中)。